Why reboot Intake?
![]()
Since it took me so long to make Intake "Take2" 2.0.0, I'll keep this post short.
Summary
So you have data that you want to do stuff with. Intake might be the connective tissue you are after.
Intake was originally well received and found a small community of users. However it never got the attention or popularity I thought it deserved. So, as one more attempt, this is my effort to make it both simpler and more powerful and see if, in a crowded marketplace, people want to give Intake a try.
What Intake?
Intake's moto has always been: "Taking the pain out of data access and distribution" The main docs are at https://intake.readthedocs.io/en/latest/ , so I won't repeat what is written there; but the gist is, data is everything these days, and anything that can be done to smooth how to locate, understand and load data, the more effective practitioners (data scientists, engineers, AI/ML modelers, analysts) will be. In the typical scenario, a given notebook or script has just some hard-coded URL/path, and the user has no idea of the target's provenance.
Intake is all-python and likes talking to all the packages that make up the "PyData" ecosystem (see numfocus, pandata and others). These packages tend to focus on one thing at a time, and play nicely with one-another with open protocols. However, there has been no data cataloguing standard. Catalogs describe your datasets, providing metadata, so that you know which data you need for a particular job, it's characteristics and how you might load it to get things ready for analysis.
A data warehouse or service might have a catalogue (e.g., unity for databricks) and even SQL servers have at least names for each table/view/query. In the more python-specific world, we have dlt, specialising in JSON->tabular, datasette for sqllite online queries and datapackage. But these are specific to platform, use case or datatype. Intake is the "everything" of data.
Why Now?
With the AI explosion, we know that CSV is not the only filetype, and indeed that tables alone don't solve everything. Experience with the zarr project, and particularly kerchunk has shown me how complex multi-dimensional array (tensor) sets can be, and awkward demonstrated the importance of vectorised operations over nested, variable-length data. Defining how to load such data can be complex!
In the meantime, dask is not the only parallel compute framework around. Ray, polars and others have shows great uptake with various lazy, query-optimised and out-of-core workflows. Old Intake was tied to dask, which was a fine choice at the time, but became more obviously outdated.
There was also pushback against the complexity of creating new plugins for Intake, especially catalogue-producing ones. It turns out, that many of the extra features of old Intake (caching, persistence, path pattern matching, the server) were very rarely used and only complicated developers' experience with Intake.
How better?
Intake will flourish in situations where:
- there are many datasets (so that finding the right one is a task)
- datasets get updated centrally (so that users would frequently have to find the "latest")
- many datatypes are needed for a job (if everything is a CSV, you only need one loading function)
- users bother to create catalogs and share them (see Anaconda's aspirational public catalog)
I removed what was unnecessary complexity, but made everything more generic, and so general-purpose. We don't depend on Dask, but any compute engine (spark, ray, duck, ...) can be and are integrated: when a datatype is declared (even something simple like "CSV"), it can be read with potentially several packages.
At its core, Intake is still "simple" and lightweight: it calls functions in other packages, but gives pointers to users to help them make pipelines, and so easily create catalogs. You can
- discover what type your data is
- generate a reader from a normal python line
- show which readers can read it
- find the path from one type to any other we support
- make pipelines using the same methods you normally would, even combining readers
- add any reader to catalog with setitem
- make new data types and readers with very minimal code
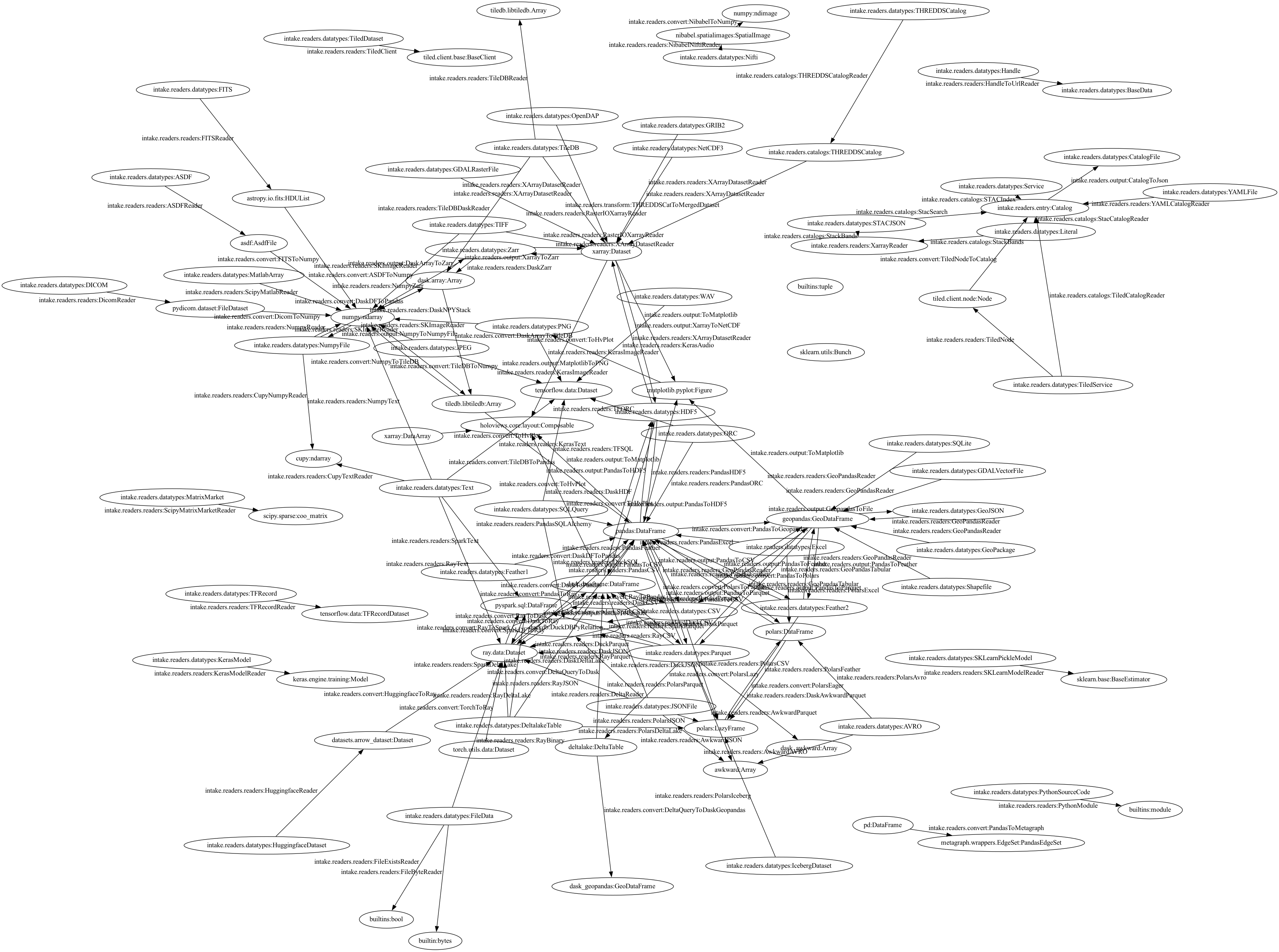
And here's the current image of all the transforms we currently supports. You can't see the detail, and that is the point: